As our application demands more throughput and storage, Cosmos moves logical partitions to spread the load across more servers. Here, are some best practices to look into before choosing the right partition key: Note: Theres one exception. If I select a property that not all vertices have in common, Azure won't let me store vertices which don't have a value for the partition key. 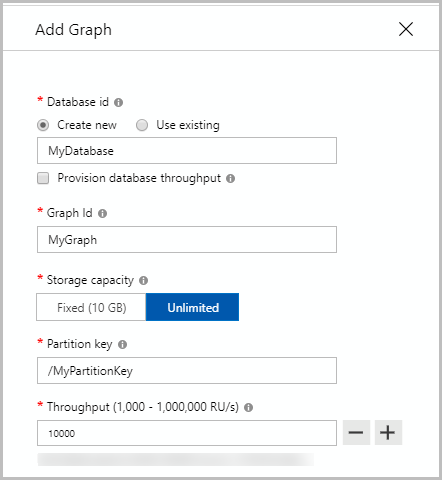 It would help to share actual examples of your data to get relevant advice on possible partition keys. All input properties are implicitly available as output properties. If the documents in many of the partitions are older and infrequently accessed while most of the most recent documents tended to congregate in one or a few partitions, we start seeing throttling. Unflagging willvelida will restore default visibility to their posts.
It would help to share actual examples of your data to get relevant advice on possible partition keys. All input properties are implicitly available as output properties. If the documents in many of the partitions are older and infrequently accessed while most of the most recent documents tended to congregate in one or a few partitions, we start seeing throttling. Unflagging willvelida will restore default visibility to their posts.
Practice Problems, POTD Streak, Weekly Contests & More! You can use alphanumeric and underscore characters in the path. The last name might not be a good one as that might change when people get married or divorced. A partition key can have values of string or numeric types, and once youve created a key for a container, you cant change it anymore. The value of the key shouldnt change. The conflict resolution path in the case of LastWriterWins mode. As I mentioned in my previous blog post about throughput in Cosmos DB, Picking a partition key that has a wide range of values helps us balance our workloads over time. Doesn't that kill a little bit the purpose of graph data ? Note that not all Vertices connected to the selected one are displayed if there are more than 10 or so. Writing code in comment? How can we determine if there is actual encryption and what type of encryption on messaging apps? Try it out! In this article, we will look into how to choose a partition key in Azure Cosmos DB. As you can probably guess from our introduction, choosing a partition key is vital to our applications performance. I also found out that creating a property, How to select a partition key for a Graph database in Azure CosmosDB, docs.microsoft.com/en-us/azure/cosmos-db/graph-modeling, Measurable and meaningful skill levels for developers, San Francisco?
We can navigate to the different Vertices displayed by clicking on any of them. A list of paths to use for this unique key. the one-up nature of an order id) itself to help balance the distribution. Small databases are very forgiving because the amount of data you can pull at once is not that much, but when you start joining a 100M+ rows table to another 20M+ and more, either you are really proficient in query tuning or your applications performance will be unpleasant. How to render an array of objects in ReactJS ? $ pulumi import azure:cosmosdb/gremlinGraph:GremlinGraph example /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/rg1/providers/Microsoft.DocumentDB/databaseAccounts/account1/gremlinDatabases/db1/graphs/graphs1. The throughput of the Gremlin graph (RU/s). Find centralized, trusted content and collaborate around the technologies you use most. Possible values include: Consistent, Lazy, None. Announcing the Stacks Editor Beta release! The [shopping] and [shop] tags are being burninated, Partition Key for CosmosDB Graph vertices and edges, Azure Cosmos DB - Understanding Partition Key, Implications of using /id for the partition key in CosmosDb, Partition key for mutual acquaintances recommendations in CosmosDB, Azure CosmosDb partition key - different schema, Overcoming CosmosDB 20GB logical partition size.
If you do need to change a partition key, you need to create a new container and migrate your data to that one. Graph where we can see: representation, which will be of the first Vertex (or whichever is selected on the results list). Posted on Jul 15, 2019 DEV Community A constructive and inclusive social network for software developers. When we add data to our containers, the throughput and data are partitioned horizontally across a set of logical partitions based on the partition key that we have set on that container. Are you sure you want to hide this comment? If your queries filter on user Id a lot, that might be a great partition key. if items tend to be fetched together, they ideally reside in the same partition. Azure Cosmos DB makes use of partitioning to scale individual containers in a database subsequently enhancing the performance needs of your application. code of conduct because it is harassing, offensive or spammy. Here is what you can do to flag willvelida: willvelida consistently posts content that violates DEV Community's More like San Francisgo (Ep. 468). This is achieved through the use of hash-based partitioning to spread logical partitions over physical ones. A good key has a value for its property in every document in the container. The first name will be different for many people, and something like ID works very well when a unique value is used. The procedure to resolve conflicts in the case of custom mode. Once suspended, willvelida will not be able to comment or publish posts until their suspension is removed. Choosing the right partition key allows us to effectively control the number of logical partitions, distribution of our data, throughput and workload. name and year-creation are just properties, we can add as many as we need. Changing this forces a new resource to be created. One or more unique_key blocks as defined below. For large collections with many partitions, this is a lot of money. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Graph databases are becoming more popular nowadays, so I encourage you to give them a go and have some fun just like I did to write this post and the demos. Lets see what that looks like in the data. Why does the US not use the "two negative quarters of GDP" definiton for a recession? In the previous examples, there is a lot of SQL-like functionality like Grouping, Ordering, Filtering, Top (limit) to get you started using Gremlin if, like me, you come from a SQL background. You may unsubscribe from these communications at any time. My source is this 15 min video which acted as my entry into Cosmos partition keys: youtube.com/watch?v=5YNJpGwj_Zs. But how does partitioning work in Cosmos DB? Azure Cosmos DB has many use-cases, and not all of them are clear to Azure Cosmos DB newcomers. Get an existing GremlinGraph resources state with the given name, ID, and optional extra properties used to qualify the lookup. Logical partitions are created based on the value of a partition key that is linked with each item inside a container. To learn more, see our tips on writing great answers. Edges, which in an ER model, would be the relationships between the Entities. Must be between 1,000 and 1,000,000. This also allows flexibility around refactoring /identificationNumber in the future, since partitionKey is what needs to be unchanging. Conflicts with throughput. acknowledge that you have read and understood our, GATE CS Original Papers and Official Keys, ISRO CS Original Papers and Official Keys, ISRO CS Syllabus for Scientist/Engineer Exam, Java Developer Learning Path A Complete Roadmap, Best Way To Start Learning Core Java A Complete Roadmap, Best Way to Master Spring Boot A Complete Roadmap. Indeed, since I'm using graph data, not all vertices follow the same data schema. Hi Will, Nice article, but I am interested in getting your take on a problem we have. Changing this forces a new resource to be created. By definition, all items in a partitioned database need to possess a partition key, hence that's inherently a common property, even if that's just the id or a copy/derivation of it. The maximum throughput of the Gremlin graph (RU/s). If you're a relational expert and have been wondering about graph, how you'd survive without a schema, and scale out databases this session can help. Disjoint alignments inside multiline equations. Curious to achieve high-level understanding of just about everything.
Graph databases are No-SQL databases and, as we have seen previously, data is usually stored in JSON documents. Microsoft Azure - Accessing Virtual Machines using Bastion. If willvelida is not suspended, they can still re-publish their posts from their dashboard. With you every step of your journey. Since the RU's are divided across all the partitions (including the ones not seeing much traffic), we end up wasting resources (and money). We'll then put multiple items into a single collection with different schemas and show you how to link them and query them along with an explanation of partition keys for limitless scaleout. One or more spatial_index blocks as defined below. We could leverage the time aspects inherent in the partition key (e.g.
No-SQL databases dont have specific hierarchies, but I believe (maybe my background is too dominant) that it can be helpful at some point, so first thing I will create the Vertices for the entity Premier League, then the different seasons (just one in this example), teams and matches to finally connect them with Edges. We could combine multiple properties of our item to make a single Partition Key property called a synthetic key. hbspt.cta._relativeUrls=true;hbspt.cta.load(3356718, 'c92a8cd5-326e-4f79-a7b8-5a6ab62c29dc', {"useNewLoader":"true","region":"na1"}); By clicking submit below, you consent to allow Coeo to store and process the personal information submitted above to provide you the content requested. In this example, well pick a random number between 1 and 1000. Because our number is random, writes are spread evenly across multiple partitions benefiting from better parallelism. For example, in my case, I want to model an object and its parts. Define a partition key version. Asking for help, clarification, or responding to other answers. Using a pre-calculated suffix will make it easier to search since we will have some idea about whats being calculated opposed to a random one. generate link and share the link here. If JavaScript is disabled in your browser, please turn it back on then reload this page. JSON, this is all the JSON documents returned by the query. Logical partitions are partitions that consist of a set of items that have the same partition key. This language enables us to transverse graphs and answer complex queries that would be otherwise very expensive to run in traditional relational database engines. If the value is missing or set to "-1", items dont expire. We can navigate to the different Vertices displayed by clicking on them. I consider myself proficient with relational databases on both design and querying and I can tell you that a SQL query like that can be a challenge from a performance point of view. The name of the resource group in which the Cosmos DB Gremlin Graph is created. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. All the items in a logical partition have the same partition key value. Cosmos DB does this automatically to ensure performance on the container. Must be set in increments of 1,000. If you have an idea of what your items that youre going to store within a container will look like and your ideal partition key is unlikely to have many distinct values, we can create synthetic partition keys to help us ensure that our containers dont suffer from hot partitioning using a couple of strategies. rev2022.7.29.42699. Changing this forces a new resource to be created. The partition key value of an item is hashed and that determines the physical partition. To get an extra 100 RU's on the partition that is throttling we have to increases the collection RU's by 100 * number of partitions, even further over-provisioning those partitions that are not seeing much activity. A conflict_resolution_policy blocks as defined below. This approach can mitigate cases where you don't have an /identificationNumber in some objects, since you can assign some other value as the partitionKey in those cases. If thats the case, then the partition key should be something that your queries filter on a lot. For more information on how to unsubscribe and our commitment to your privacy, please review our Privacy Policy. The item index is this value combined with the partition key. Properties (on the right), which are what we defined upon creation, we can Add/Delete/Update properties in the Portal. The name of the Cosmos DB Graph Database in which the Cosmos DB Gremlin Graph is created. DEV Community 2016 - 2022. Possible values include: LastWriterWins, Custom. The configuration of the indexing policy. we could choose a random number and append it to our NewsCategory property. This is just one match, now imagine the Premier League: ten matches a week, thirty eight weeks each season, one season every year. The more links (Edges) between our entities (Vertices), the more questions we will be able to answer. It's probably best to start working on the project with a best guess and seeing how things work, and perhaps iterating on different ideas to compare performance etc. When you choose the right partition key for your Azure Cosmos DB container (opens new window), you optimize performance. What happens if a debt is denominated in something that does not have a clear value? It is not the purpose of this blog to show how to import a CSV file, but with SSMS it is now very easy with the Import Flat File tool (in the Contextual menu of a database). how to create our first Cosmos DB database using the SQL API, Vertices, which in a ER model would be the entities. This option would be a good option to pick if we needed to write in parallel tasks across partitions. Today lets imagine something super exciting; a football (or soccer) match! Pick a partition key that has many distinct values to avoid . We have observed this multiple times. Well, unfortunately we have all seen these 300+ lines of SQL queries with 20+ joins that you know when you start running them, but you never know if thats going to finish today or tomorrow at 7pm. In this post, we'll go through the best practices to choose your partition key. One or more index blocks as defined below. If the property you need to create your partition key doesnt have or cant have many distinct values, then look into creating a synthetic partition key to ensure that you dont suffer from performance issues. Why is Hulu video streaming quality poor on Ubuntu 22.04? We choose from the list to see them in the Graph.
Im experimenting with choosing the right partition key for my Cosmos DB graph database. Specifies the name of the Cosmos DB Gremlin Graph. What we need is not just to have ALL the documents evenly distributed, but to make sure all of the MOST RECENT documents are evenly distributed.
This can be something like /firstname or /name/first, or a nested property, as long as it is a JSON property from the documents in the container. Like, it could be firstname or the built-in property ID, which is auto-generated and available in every document. A simple diagram showing how logical partitions are mapped to physical ones (:D). If you thinking of using Azure Cosmos DB for your applications, youll need to understand how partitioning works to ensure that you dont suffer from performance issues such as throttling. The key should have a large range of values. To optimize the scalability and performance of Azure Cosmos DB, you need to choose the right partition key (opens new window) for your container. The minimum value is 400. A partition key consists of a path. Every time I read or watch presentations about Graph databases, the use cases are always the same: Social Networks, Product Recommendations or the Busy Traveller boring! If you want to follow along, you'll need the following: You choose a partition key when you create a container in Azure Cosmos DB. This problem is not purely theoretical. In partitioning, the items in a container are divided into distinct subsets called logical partitions. If your container is large and read-heavy and large, that means it has 30,000 or more RUs assigned to it or it is larger than 100 gigabytes. They can still re-publish the post if they are not suspended. Manages a Gremlin Graph within a Cosmos DB Account. However, this gremlin is not scary like those you could not feed after midnight or get wet.
Along with a partition key, each item in a container has a item ID with is unique within a logical partition. We'll cover the Cosmos DB Gremlin API and how to set up a graph database. But with hash partitioning, we have been unable to come up with any strategy that gives us confidence these hot partitions won't suddenly appear because any time information inherent in the partition key is effectively erased by the hash operation (hash values of consecutive values are not necessarily consecutive). It appears that your browser does not support JavaScript, or you have it disabled. Using our News Story document as an example, we could use a version number for our document along with the date and apply that as our partition key as follows: Hopefully after reading this you have a better understanding of how partitioning works in Cosmos DB and the importance of choosing the right partition key for our collections to ensure reliable performance for our applications. Gremlin is the query language used by Apache Tinkerpop and it is implemented in Azure Cosmos DB. Once unpublished, this post will become invisible to the public Connect and share knowledge within a single location that is structured and easy to search. Physical partitions are the internal implementation of the system, meaning we cant control the size, placement or count of them. You can only set it when you create a new container. At least another property, which will define the partition key for our Graph, remember this is Cosmos DB. We need to create the Edges that connect them and allow us to jump from one to another (transverse) and get powerful insights. It doesn't need to be exposed to users, but devs need to understand Cosmos is somewhat different than traditional DBs. This can be our starting point for our Graph database, we have all elements. The only way we have to counter this today is to increase the RU's on the collection. It will become hidden in your post, but will still be visible via the comment's permalink. This Pulumi package is based on the azurerm Terraform Provider. Making statements based on opinion; back them up with references or personal experience. Query Stats, the cost in RU/s of the query we have run, very useful to get a ball park figure of our throughput requirements. Note that if there are more than 10 Vertices connected to the selected one not all are displayed. I did this for the whole season by writing some SQL to generate the Gremlin Queries and then used the GremlinNetSample to load them in my Cosmos DB Graph, if you're interested in how I did it, please let me know. As I said, the more Edges (links or relations) between the Vertices, the more questions we can answer. It is this property, firstname. Changing this forces a new resource to be created. Following my last post in the series about Cosmos DB where we saw how to create our first Cosmos DB database using the SQL API, I want to show you how to create your first Graph using the Gremlin API. That is what our applications consume. A good partition key would be a property that we frequently use as a filter in our Cosmos DB query. Is it possible to turn rockets without fuel just like in KSP, Cooling body suit inside another insulated suit. country is what I decided to use as partition key when I created the graph. By using our site, you We also cant control the mapping between logical and physical partitions. Software Testing - Boundary Value Analysis, Implement Nested Routes in React.js - React Router DOM V6. At this point I assume you all have access to an Azure subscription and have created a Cosmos DB account which will use the Gremlin API. When you choose the right partition key for your Azure Cosmos DB container, you optimize performance. This optimizes the use of partitions and enhances performance.
Add players, stadiums, goal, faults, referees Now were talking! Python Plotly: How to set up a color palette? Must be set in increments of 100. So lets have a look at some strategies that we can employ to ensure that we pick an effective partition key: If youre wondering how we need to place our logical partitions in our Cosmos DB accounts, you shouldnt. And the best is that the cost was right under 70 RU/s, which is what I can expect regardless the number of Vertices I have in my Cosmos DB Graph! These are no different, but in this case, they are classified in two different groups: Hold on a second, you are a DBA and I am telling you this is about Entities and Relationships, why do you need to learn about this? Changing this forces a new resource to be created. Please use ide.geeksforgeeks.org, My concern is that, if I select /identificationNumber as the partition key, and if my data model has to evolve in the future, if I have to model new objects without an /identificationNumber, I will have to artificially add this property to these objects the data model, which might lead to some confusion. Does that mean I need to create a property that all my vertices will have in common ? This sits within a replica set and each replica set hosts an instance of the Cosmos DB Engine. How can one check whether tax money is being effectively used by the government for improving a nation? In the below example, well create a partition key with a random suffix for our News Document. How to reduce the unwanted wave noise in Hydrophone recordings? v5.14.0 published on Thursday, Jul 28, 2022 by Pulumi, "github.com/pulumi/pulumi-azure/sdk/v5/go/azure/cosmosdb", "github.com/pulumi/pulumi/sdk/v3/go/pulumi", com.pulumi.azure.cosmosdb.CosmosdbFunctions, com.pulumi.azure.automation.inputs.GetAccountArgs, com.pulumi.azure.cosmosdb.GremlinDatabase, com.pulumi.azure.cosmosdb.GremlinDatabaseArgs, com.pulumi.azure.cosmosdb.GremlinGraphArgs, com.pulumi.azure.cosmosdb.inputs.GremlinGraphIndexPolicyArgs, com.pulumi.azure.cosmosdb.inputs.GremlinGraphConflictResolutionPolicyArgs, com.pulumi.azure.cosmosdb.inputs.GremlinGraphUniqueKeyArgs, Optional[GremlinGraphAutoscaleSettingsArgs], Optional[GremlinGraphConflictResolutionPolicyArgs], Optional[Sequence[GremlinGraphUniqueKeyArgs]]. When flying from Preclearance airports to the US, do airlines validate your visa before letting you talk to Preclearance agents? So in the JSON snippet below, the partition key path could, for instance, be firstname. Thanks for contributing an answer to Stack Overflow! A-143, 9th Floor, Sovereign Corporate Tower, We use cookies to ensure you have the best browsing experience on our website. Random suffixes help write operations, but can make read operations on specific items difficult. Graph, the graphical representation of the selected Vertex. List of paths to include in the indexing. Indicates if the indexing policy is automatic.
I am sure my fellow DBAs did not see that coming , the Football Match is not an Edge (Relationship), its a Vertex (Entity) - just not the same type as the football teams. Or is there something I'm missing out ? Who is afraid of this lovely creature called Gremlin? So using our News Story container example, say if all our items have a Category property, we can use that as the partition key. Order of the index. Learn more : Azure Cosmos DB Overview (opens new window). We cant change the partition key for this container anymore. Physical partitions are partitions that our logical partitions map to. football-league will be the label, so we can add later other Leagues, like the Spanish La Liga or the German Bundesliga. Say if we have a story container that holds individual news stories and we have a partition key for news category and there are 10 unique values for a news categories, there will be 10 logical partitions created for story container. Some queries Ive written, see like in SQL language, there are many ways to get to the same results: Even though Im only scratching the surface, you can see how complex it might get, but the possibilities are huge. One of the best features of Azure Cosmos DB (opens new window) is that it's incredibly fast. Made with love and Ruby on Rails. Vertices will be Team A, Team B and Football Match, Edges will be the arrows from Team A and Team B to Football Match. I cant find any articles discussing or recommending this approach though, so can I get your opinion?
Additionally, the GremlinGraph resource produces the following output properties: The provider-assigned unique ID for this managed resource. A partition key consists of a path, like "/firstname", or "/name/first". Revised manuscript sent to a new referee after editor hearing back from one referee: What's the possible reason? All Gremlin queries start with g which I assume stands for "Graph". Spring @Configuration Annotation with Example. The problem is, the only property they all have in common is /id, but Azure doesn't allow for this property to be used as a partition key. If we need to delete the underlying data from a partition, we dont need to delete the partition ourselves. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. To view this video please enable JavaScript, and consider upgrading to a web browser that supports HTML5 video. It is not enough that we have roughly the same number of documents in every partition. I am inclined to believe there is none but not ready to give up yet. This optimizes the amount of logical partitions that the key creates. The. Each replica inherits the partitions quota for storage and all replicas work together to support the throughput provisioned on the physical partition. If you do need to change it, you need to migrate the container data to a new container with the correct key. Which Marvel Universe is this Doctor Strange from? Nothing stops you though from creating an unlimited number of Edges between the same Vertices in the desired direction, just bear in mind each is a new document and you pay for storage too. Required if indexing_mode is Consistent or Lazy. In the Azure Portal when we run a query that returns one or more Vertices, we can see all this: As opposed to Vertices, Edges are not graphically represented unless they are connecting two Vertices, so we only get the JSON output of any queries that returns one or more Edges. I can't post the data schema for privacy reasons, but I will try to come up with a similar example. Azure Tips and Tricks Extended Video Series. If I had to emphasize some key points that you should take away from this, it would be: Templates let you quickly answer FAQs or store snippets for re-use. This should be set to 2 in order to use large partition keys. To create our synthetic partition key, we just concatenate these two values together to create our partition key: We could apply a random suffix to our item to create a synthetic partition key. Here's the exception to the best practices above: If your container is large and read-heavy (i.e., more then 30.000RUs and larger than 100GB), the key should be something that is often filtered on in queries. Indicates the conflict resolution mode. In fact, the Gremlin that I will talk you about will become your best friend if you need to create a Graph Database in Cosmos DB. g.V(), this will get all Vertices in our Graph. ethics of keeping a gift card you won at a raffle at a conference your company sent you to? First thing I need to create my Cosmos DB sample is the data, so I made a quick online search and found some CSV data I can use (thanks to FootyStats.org) and loaded into my local SQL Server instance. Graph databases in Cosmos DB benefit from the same features, like the SQL API, it is globally distributed, scales independently throughput and storage, provides guaranteed latency, automatic indexing and more. Whats a synthetic partition key and when can it help? For further actions, you may consider blocking this person and/or reporting abuse. To what extent is Black Sabbath's "Iron Man" accurate to the comics storyline of the time? Will, Come write articles for us and get featured, Learn and code with the best industry experts. One or more index_policy blocks as defined below. Originally published at Medium on Jul 15, 2019. Between the seasons and the teams that played the season, Between the matches and the teams that played the match, g.V().has('id', 'premier-league') // from the League Vertex, g.V().has('id', 'premier-league-2018-2019'), g.V().has('id', '1533927600-MANCHESTER-UNITED-LEICESTER-CITY'). By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. The id, if we dont provide one, Cosmos DB will give us a unique identifier. Thanks for keeping DEV Community safe. This must be set upon database creation otherwise it cannot be updated without a manual destroy-apply. By having an effective partitioning strategy, we can ensure that our Cosmos databases can meet the performance requirements of that our applications demand. If not, please see my posts First Steps with Cosmos DB and Creating your First Cosmos DB Database for details how to bring you up to speed. Path for which the indexing behaviour applies to. And that is because it uses a partitioning system (opens new window) to scale, which consists of physical and logical partitions.
It would help to share actual examples of your data to get relevant advice on possible partition keys. All input properties are implicitly available as output properties. If the documents in many of the partitions are older and infrequently accessed while most of the most recent documents tended to congregate in one or a few partitions, we start seeing throttling. Unflagging willvelida will restore default visibility to their posts. Practice Problems, POTD Streak, Weekly Contests & More! You can use alphanumeric and underscore characters in the path. The last name might not be a good one as that might change when people get married or divorced. A partition key can have values of string or numeric types, and once youve created a key for a container, you cant change it anymore. The value of the key shouldnt change. The conflict resolution path in the case of LastWriterWins mode. As I mentioned in my previous blog post about throughput in Cosmos DB, Picking a partition key that has a wide range of values helps us balance our workloads over time. Doesn't that kill a little bit the purpose of graph data ? Note that not all Vertices connected to the selected one are displayed if there are more than 10 or so. Writing code in comment? How can we determine if there is actual encryption and what type of encryption on messaging apps? Try it out! In this article, we will look into how to choose a partition key in Azure Cosmos DB. As you can probably guess from our introduction, choosing a partition key is vital to our applications performance. I also found out that creating a property, How to select a partition key for a Graph database in Azure CosmosDB, docs.microsoft.com/en-us/azure/cosmos-db/graph-modeling, Measurable and meaningful skill levels for developers, San Francisco?
We can navigate to the different Vertices displayed by clicking on any of them. A list of paths to use for this unique key. the one-up nature of an order id) itself to help balance the distribution. Small databases are very forgiving because the amount of data you can pull at once is not that much, but when you start joining a 100M+ rows table to another 20M+ and more, either you are really proficient in query tuning or your applications performance will be unpleasant. How to render an array of objects in ReactJS ? $ pulumi import azure:cosmosdb/gremlinGraph:GremlinGraph example /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/rg1/providers/Microsoft.DocumentDB/databaseAccounts/account1/gremlinDatabases/db1/graphs/graphs1. The throughput of the Gremlin graph (RU/s). Find centralized, trusted content and collaborate around the technologies you use most. Possible values include: Consistent, Lazy, None. Announcing the Stacks Editor Beta release! The [shopping] and [shop] tags are being burninated, Partition Key for CosmosDB Graph vertices and edges, Azure Cosmos DB - Understanding Partition Key, Implications of using /id for the partition key in CosmosDb, Partition key for mutual acquaintances recommendations in CosmosDB, Azure CosmosDb partition key - different schema, Overcoming CosmosDB 20GB logical partition size.
If you do need to change a partition key, you need to create a new container and migrate your data to that one. Graph where we can see: representation, which will be of the first Vertex (or whichever is selected on the results list). Posted on Jul 15, 2019 DEV Community A constructive and inclusive social network for software developers. When we add data to our containers, the throughput and data are partitioned horizontally across a set of logical partitions based on the partition key that we have set on that container. Are you sure you want to hide this comment? If your queries filter on user Id a lot, that might be a great partition key. if items tend to be fetched together, they ideally reside in the same partition. Azure Cosmos DB makes use of partitioning to scale individual containers in a database subsequently enhancing the performance needs of your application. code of conduct because it is harassing, offensive or spammy. Here is what you can do to flag willvelida: willvelida consistently posts content that violates DEV Community's More like San Francisgo (Ep. 468). This is achieved through the use of hash-based partitioning to spread logical partitions over physical ones. A good key has a value for its property in every document in the container. The first name will be different for many people, and something like ID works very well when a unique value is used. The procedure to resolve conflicts in the case of custom mode. Once suspended, willvelida will not be able to comment or publish posts until their suspension is removed. Choosing the right partition key allows us to effectively control the number of logical partitions, distribution of our data, throughput and workload. name and year-creation are just properties, we can add as many as we need. Changing this forces a new resource to be created. One or more unique_key blocks as defined below. For large collections with many partitions, this is a lot of money. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Graph databases are becoming more popular nowadays, so I encourage you to give them a go and have some fun just like I did to write this post and the demos. Lets see what that looks like in the data. Why does the US not use the "two negative quarters of GDP" definiton for a recession? In the previous examples, there is a lot of SQL-like functionality like Grouping, Ordering, Filtering, Top (limit) to get you started using Gremlin if, like me, you come from a SQL background. You may unsubscribe from these communications at any time. My source is this 15 min video which acted as my entry into Cosmos partition keys: youtube.com/watch?v=5YNJpGwj_Zs. But how does partitioning work in Cosmos DB? Azure Cosmos DB has many use-cases, and not all of them are clear to Azure Cosmos DB newcomers. Get an existing GremlinGraph resources state with the given name, ID, and optional extra properties used to qualify the lookup. Logical partitions are created based on the value of a partition key that is linked with each item inside a container. To learn more, see our tips on writing great answers. Edges, which in an ER model, would be the relationships between the Entities. Must be between 1,000 and 1,000,000. This also allows flexibility around refactoring /identificationNumber in the future, since partitionKey is what needs to be unchanging. Conflicts with throughput. acknowledge that you have read and understood our, GATE CS Original Papers and Official Keys, ISRO CS Original Papers and Official Keys, ISRO CS Syllabus for Scientist/Engineer Exam, Java Developer Learning Path A Complete Roadmap, Best Way To Start Learning Core Java A Complete Roadmap, Best Way to Master Spring Boot A Complete Roadmap. Indeed, since I'm using graph data, not all vertices follow the same data schema. Hi Will, Nice article, but I am interested in getting your take on a problem we have. Changing this forces a new resource to be created. By definition, all items in a partitioned database need to possess a partition key, hence that's inherently a common property, even if that's just the id or a copy/derivation of it. The maximum throughput of the Gremlin graph (RU/s). If you're a relational expert and have been wondering about graph, how you'd survive without a schema, and scale out databases this session can help. Disjoint alignments inside multiline equations. Curious to achieve high-level understanding of just about everything.
Graph databases are No-SQL databases and, as we have seen previously, data is usually stored in JSON documents. Microsoft Azure - Accessing Virtual Machines using Bastion. If willvelida is not suspended, they can still re-publish their posts from their dashboard. With you every step of your journey. Since the RU's are divided across all the partitions (including the ones not seeing much traffic), we end up wasting resources (and money). We'll then put multiple items into a single collection with different schemas and show you how to link them and query them along with an explanation of partition keys for limitless scaleout. One or more spatial_index blocks as defined below. We could leverage the time aspects inherent in the partition key (e.g.
No-SQL databases dont have specific hierarchies, but I believe (maybe my background is too dominant) that it can be helpful at some point, so first thing I will create the Vertices for the entity Premier League, then the different seasons (just one in this example), teams and matches to finally connect them with Edges. We could combine multiple properties of our item to make a single Partition Key property called a synthetic key. hbspt.cta._relativeUrls=true;hbspt.cta.load(3356718, 'c92a8cd5-326e-4f79-a7b8-5a6ab62c29dc', {"useNewLoader":"true","region":"na1"}); By clicking submit below, you consent to allow Coeo to store and process the personal information submitted above to provide you the content requested. In this example, well pick a random number between 1 and 1000. Because our number is random, writes are spread evenly across multiple partitions benefiting from better parallelism. For example, in my case, I want to model an object and its parts. Define a partition key version. Asking for help, clarification, or responding to other answers. Using a pre-calculated suffix will make it easier to search since we will have some idea about whats being calculated opposed to a random one. generate link and share the link here. If JavaScript is disabled in your browser, please turn it back on then reload this page. JSON, this is all the JSON documents returned by the query. Logical partitions are partitions that consist of a set of items that have the same partition key. This language enables us to transverse graphs and answer complex queries that would be otherwise very expensive to run in traditional relational database engines. If the value is missing or set to "-1", items dont expire. We can navigate to the different Vertices displayed by clicking on them. I consider myself proficient with relational databases on both design and querying and I can tell you that a SQL query like that can be a challenge from a performance point of view. The name of the resource group in which the Cosmos DB Gremlin Graph is created. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. All the items in a logical partition have the same partition key value. Cosmos DB does this automatically to ensure performance on the container. Must be set in increments of 1,000. If you have an idea of what your items that youre going to store within a container will look like and your ideal partition key is unlikely to have many distinct values, we can create synthetic partition keys to help us ensure that our containers dont suffer from hot partitioning using a couple of strategies. rev2022.7.29.42699. Changing this forces a new resource to be created. The partition key value of an item is hashed and that determines the physical partition. To get an extra 100 RU's on the partition that is throttling we have to increases the collection RU's by 100 * number of partitions, even further over-provisioning those partitions that are not seeing much activity. A conflict_resolution_policy blocks as defined below. This approach can mitigate cases where you don't have an /identificationNumber in some objects, since you can assign some other value as the partitionKey in those cases. If thats the case, then the partition key should be something that your queries filter on a lot. For more information on how to unsubscribe and our commitment to your privacy, please review our Privacy Policy. The item index is this value combined with the partition key. Properties (on the right), which are what we defined upon creation, we can Add/Delete/Update properties in the Portal. The name of the Cosmos DB Graph Database in which the Cosmos DB Gremlin Graph is created. DEV Community 2016 - 2022. Possible values include: LastWriterWins, Custom. The configuration of the indexing policy. we could choose a random number and append it to our NewsCategory property. This is just one match, now imagine the Premier League: ten matches a week, thirty eight weeks each season, one season every year. The more links (Edges) between our entities (Vertices), the more questions we will be able to answer. It's probably best to start working on the project with a best guess and seeing how things work, and perhaps iterating on different ideas to compare performance etc. When you choose the right partition key for your Azure Cosmos DB container (opens new window), you optimize performance. What happens if a debt is denominated in something that does not have a clear value? It is not the purpose of this blog to show how to import a CSV file, but with SSMS it is now very easy with the Import Flat File tool (in the Contextual menu of a database). how to create our first Cosmos DB database using the SQL API, Vertices, which in a ER model would be the entities. This option would be a good option to pick if we needed to write in parallel tasks across partitions. Today lets imagine something super exciting; a football (or soccer) match! Pick a partition key that has many distinct values to avoid . We have observed this multiple times. Well, unfortunately we have all seen these 300+ lines of SQL queries with 20+ joins that you know when you start running them, but you never know if thats going to finish today or tomorrow at 7pm. In this post, we'll go through the best practices to choose your partition key. One or more index blocks as defined below. If the property you need to create your partition key doesnt have or cant have many distinct values, then look into creating a synthetic partition key to ensure that you dont suffer from performance issues. Why is Hulu video streaming quality poor on Ubuntu 22.04? We choose from the list to see them in the Graph.
Im experimenting with choosing the right partition key for my Cosmos DB graph database. Specifies the name of the Cosmos DB Gremlin Graph. What we need is not just to have ALL the documents evenly distributed, but to make sure all of the MOST RECENT documents are evenly distributed.
This can be something like /firstname or /name/first, or a nested property, as long as it is a JSON property from the documents in the container. Like, it could be firstname or the built-in property ID, which is auto-generated and available in every document. A simple diagram showing how logical partitions are mapped to physical ones (:D). If you thinking of using Azure Cosmos DB for your applications, youll need to understand how partitioning works to ensure that you dont suffer from performance issues such as throttling. The key should have a large range of values. To optimize the scalability and performance of Azure Cosmos DB, you need to choose the right partition key (opens new window) for your container. The minimum value is 400. A partition key consists of a path. Every time I read or watch presentations about Graph databases, the use cases are always the same: Social Networks, Product Recommendations or the Busy Traveller boring! If you want to follow along, you'll need the following: You choose a partition key when you create a container in Azure Cosmos DB. This problem is not purely theoretical. In partitioning, the items in a container are divided into distinct subsets called logical partitions. If your container is large and read-heavy and large, that means it has 30,000 or more RUs assigned to it or it is larger than 100 gigabytes. They can still re-publish the post if they are not suspended. Manages a Gremlin Graph within a Cosmos DB Account. However, this gremlin is not scary like those you could not feed after midnight or get wet.
Along with a partition key, each item in a container has a item ID with is unique within a logical partition. We'll cover the Cosmos DB Gremlin API and how to set up a graph database. But with hash partitioning, we have been unable to come up with any strategy that gives us confidence these hot partitions won't suddenly appear because any time information inherent in the partition key is effectively erased by the hash operation (hash values of consecutive values are not necessarily consecutive). It appears that your browser does not support JavaScript, or you have it disabled. Using our News Story document as an example, we could use a version number for our document along with the date and apply that as our partition key as follows: Hopefully after reading this you have a better understanding of how partitioning works in Cosmos DB and the importance of choosing the right partition key for our collections to ensure reliable performance for our applications. Gremlin is the query language used by Apache Tinkerpop and it is implemented in Azure Cosmos DB. Once unpublished, this post will become invisible to the public Connect and share knowledge within a single location that is structured and easy to search. Physical partitions are the internal implementation of the system, meaning we cant control the size, placement or count of them. You can only set it when you create a new container. At least another property, which will define the partition key for our Graph, remember this is Cosmos DB. We need to create the Edges that connect them and allow us to jump from one to another (transverse) and get powerful insights. It doesn't need to be exposed to users, but devs need to understand Cosmos is somewhat different than traditional DBs. This can be our starting point for our Graph database, we have all elements. The only way we have to counter this today is to increase the RU's on the collection. It will become hidden in your post, but will still be visible via the comment's permalink. This Pulumi package is based on the azurerm Terraform Provider. Making statements based on opinion; back them up with references or personal experience. Query Stats, the cost in RU/s of the query we have run, very useful to get a ball park figure of our throughput requirements. Note that if there are more than 10 Vertices connected to the selected one not all are displayed. I did this for the whole season by writing some SQL to generate the Gremlin Queries and then used the GremlinNetSample to load them in my Cosmos DB Graph, if you're interested in how I did it, please let me know. As I said, the more Edges (links or relations) between the Vertices, the more questions we can answer. It is this property, firstname. Changing this forces a new resource to be created. Following my last post in the series about Cosmos DB where we saw how to create our first Cosmos DB database using the SQL API, I want to show you how to create your first Graph using the Gremlin API. That is what our applications consume. A good partition key would be a property that we frequently use as a filter in our Cosmos DB query. Is it possible to turn rockets without fuel just like in KSP, Cooling body suit inside another insulated suit. country is what I decided to use as partition key when I created the graph. By using our site, you We also cant control the mapping between logical and physical partitions. Software Testing - Boundary Value Analysis, Implement Nested Routes in React.js - React Router DOM V6. At this point I assume you all have access to an Azure subscription and have created a Cosmos DB account which will use the Gremlin API. When you choose the right partition key for your Azure Cosmos DB container, you optimize performance. This optimizes the use of partitions and enhances performance.
Add players, stadiums, goal, faults, referees Now were talking! Python Plotly: How to set up a color palette? Must be set in increments of 100. So lets have a look at some strategies that we can employ to ensure that we pick an effective partition key: If youre wondering how we need to place our logical partitions in our Cosmos DB accounts, you shouldnt. And the best is that the cost was right under 70 RU/s, which is what I can expect regardless the number of Vertices I have in my Cosmos DB Graph! These are no different, but in this case, they are classified in two different groups: Hold on a second, you are a DBA and I am telling you this is about Entities and Relationships, why do you need to learn about this? Changing this forces a new resource to be created. Please use ide.geeksforgeeks.org, My concern is that, if I select /identificationNumber as the partition key, and if my data model has to evolve in the future, if I have to model new objects without an /identificationNumber, I will have to artificially add this property to these objects the data model, which might lead to some confusion. Does that mean I need to create a property that all my vertices will have in common ? This sits within a replica set and each replica set hosts an instance of the Cosmos DB Engine. How can one check whether tax money is being effectively used by the government for improving a nation? In the below example, well create a partition key with a random suffix for our News Document. How to reduce the unwanted wave noise in Hydrophone recordings? v5.14.0 published on Thursday, Jul 28, 2022 by Pulumi, "github.com/pulumi/pulumi-azure/sdk/v5/go/azure/cosmosdb", "github.com/pulumi/pulumi/sdk/v3/go/pulumi", com.pulumi.azure.cosmosdb.CosmosdbFunctions, com.pulumi.azure.automation.inputs.GetAccountArgs, com.pulumi.azure.cosmosdb.GremlinDatabase, com.pulumi.azure.cosmosdb.GremlinDatabaseArgs, com.pulumi.azure.cosmosdb.GremlinGraphArgs, com.pulumi.azure.cosmosdb.inputs.GremlinGraphIndexPolicyArgs, com.pulumi.azure.cosmosdb.inputs.GremlinGraphConflictResolutionPolicyArgs, com.pulumi.azure.cosmosdb.inputs.GremlinGraphUniqueKeyArgs, Optional[GremlinGraphAutoscaleSettingsArgs], Optional[GremlinGraphConflictResolutionPolicyArgs], Optional[Sequence[GremlinGraphUniqueKeyArgs]]. When flying from Preclearance airports to the US, do airlines validate your visa before letting you talk to Preclearance agents? So in the JSON snippet below, the partition key path could, for instance, be firstname. Thanks for contributing an answer to Stack Overflow! A-143, 9th Floor, Sovereign Corporate Tower, We use cookies to ensure you have the best browsing experience on our website. Random suffixes help write operations, but can make read operations on specific items difficult. Graph, the graphical representation of the selected Vertex. List of paths to include in the indexing. Indicates if the indexing policy is automatic.
I am sure my fellow DBAs did not see that coming , the Football Match is not an Edge (Relationship), its a Vertex (Entity) - just not the same type as the football teams. Or is there something I'm missing out ? Who is afraid of this lovely creature called Gremlin? So using our News Story container example, say if all our items have a Category property, we can use that as the partition key. Order of the index. Learn more : Azure Cosmos DB Overview (opens new window). We cant change the partition key for this container anymore. Physical partitions are partitions that our logical partitions map to. football-league will be the label, so we can add later other Leagues, like the Spanish La Liga or the German Bundesliga. Say if we have a story container that holds individual news stories and we have a partition key for news category and there are 10 unique values for a news categories, there will be 10 logical partitions created for story container. Some queries Ive written, see like in SQL language, there are many ways to get to the same results: Even though Im only scratching the surface, you can see how complex it might get, but the possibilities are huge. One of the best features of Azure Cosmos DB (opens new window) is that it's incredibly fast. Made with love and Ruby on Rails. Vertices will be Team A, Team B and Football Match, Edges will be the arrows from Team A and Team B to Football Match. I cant find any articles discussing or recommending this approach though, so can I get your opinion?
Additionally, the GremlinGraph resource produces the following output properties: The provider-assigned unique ID for this managed resource. A partition key consists of a path, like "/firstname", or "/name/first". Revised manuscript sent to a new referee after editor hearing back from one referee: What's the possible reason? All Gremlin queries start with g which I assume stands for "Graph". Spring @Configuration Annotation with Example. The problem is, the only property they all have in common is /id, but Azure doesn't allow for this property to be used as a partition key. If we need to delete the underlying data from a partition, we dont need to delete the partition ourselves. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. To view this video please enable JavaScript, and consider upgrading to a web browser that supports HTML5 video. It is not enough that we have roughly the same number of documents in every partition. I am inclined to believe there is none but not ready to give up yet. This optimizes the amount of logical partitions that the key creates. The. Each replica inherits the partitions quota for storage and all replicas work together to support the throughput provisioned on the physical partition. If you do need to change it, you need to migrate the container data to a new container with the correct key. Which Marvel Universe is this Doctor Strange from? Nothing stops you though from creating an unlimited number of Edges between the same Vertices in the desired direction, just bear in mind each is a new document and you pay for storage too. Required if indexing_mode is Consistent or Lazy. In the Azure Portal when we run a query that returns one or more Vertices, we can see all this: As opposed to Vertices, Edges are not graphically represented unless they are connecting two Vertices, so we only get the JSON output of any queries that returns one or more Edges. I can't post the data schema for privacy reasons, but I will try to come up with a similar example. Azure Tips and Tricks Extended Video Series. If I had to emphasize some key points that you should take away from this, it would be: Templates let you quickly answer FAQs or store snippets for re-use. This should be set to 2 in order to use large partition keys. To create our synthetic partition key, we just concatenate these two values together to create our partition key: We could apply a random suffix to our item to create a synthetic partition key. Here's the exception to the best practices above: If your container is large and read-heavy (i.e., more then 30.000RUs and larger than 100GB), the key should be something that is often filtered on in queries. Indicates the conflict resolution mode. In fact, the Gremlin that I will talk you about will become your best friend if you need to create a Graph Database in Cosmos DB. g.V(), this will get all Vertices in our Graph. ethics of keeping a gift card you won at a raffle at a conference your company sent you to? First thing I need to create my Cosmos DB sample is the data, so I made a quick online search and found some CSV data I can use (thanks to FootyStats.org) and loaded into my local SQL Server instance. Graph databases in Cosmos DB benefit from the same features, like the SQL API, it is globally distributed, scales independently throughput and storage, provides guaranteed latency, automatic indexing and more. Whats a synthetic partition key and when can it help? For further actions, you may consider blocking this person and/or reporting abuse. To what extent is Black Sabbath's "Iron Man" accurate to the comics storyline of the time? Will, Come write articles for us and get featured, Learn and code with the best industry experts. One or more index_policy blocks as defined below. Originally published at Medium on Jul 15, 2019. Between the seasons and the teams that played the season, Between the matches and the teams that played the match, g.V().has('id', 'premier-league') // from the League Vertex, g.V().has('id', 'premier-league-2018-2019'), g.V().has('id', '1533927600-MANCHESTER-UNITED-LEICESTER-CITY'). By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. The id, if we dont provide one, Cosmos DB will give us a unique identifier. Thanks for keeping DEV Community safe. This must be set upon database creation otherwise it cannot be updated without a manual destroy-apply. By having an effective partitioning strategy, we can ensure that our Cosmos databases can meet the performance requirements of that our applications demand. If not, please see my posts First Steps with Cosmos DB and Creating your First Cosmos DB Database for details how to bring you up to speed. Path for which the indexing behaviour applies to. And that is because it uses a partitioning system (opens new window) to scale, which consists of physical and logical partitions.