AI-based SEO can ensure that one gets precise ROI tracking. Crawler-based search engines have three major components. Date published June 30, 2003 Categories. Following are majority steps involved in the working of a search engine: Crawling: Process of fetching all the web pages linked to a website. Google and Yahoo are examples of crawler search engines. Ease of use. You can extract data from more than one page, keywords, and categories. The programs used by the search engines to access your web pages are called spiders, crawlers, robots or bots. Ryan CapletCSE 4904 Fall 08Milestone 1Sept 17, 2008Crawler Based Search EngineBackground:The purpose of this project is to design a crawler-based search engi It can be used for a wide range of purposes, from data mining to monitoring and automated testing. Crawler based search engines: All crawler based search engines use a crawler or bot or spider for crawling and indexing new content to the search database. Features: This free website crawler can handle form submission, login, etc. crawler-based search engines. real-time search engines) may collect and assess items at the time of the search query, dynamically considering additional items based on the contents of a starting item (known as a seed, or seed URL in the case of an Internet crawler). The help of artificial intelligence in search engine optimisation, Website owners can enhance the user experience on their website. After a crawler finds a page, the search engine renders it just like a browser would.
Examples of Web Based Search Engines: Google: Very Firstly and most obviously, Google is the most used and most popular search Engine around the Globe that uses Crawlers or bots to index results on a Computer programs spiders build them not by human selection.
1 Components of a crawler-based search engine. The Anatomy of a Large-Scale Hypertextual Web Search Engine Sergey Brin and Lawrence Page {sergey, page}@cs.stanford.edu Computer Science Department, Stanford University, Stanford, CA 94305 Abstract In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Indexing. Todays search engines rely on software packages called spiders or robots. Open Source Web Crawler in Python: 1. They are not organized by subject categories; a computer algorithm ranks all pages.
Crawler is a program that can download web content and then follow hyperlinks within these web contents to download the linked contents. Danny Sullivan. A search interface is built in that provides better results than any NZB site or Usenet search engine. ; B2B Website Lead Generation Improve landing pages, monitor activity and escalate conversions. A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. mnoGoSearch is a crawler, indexer and a search engine written in C and licensed under the GPL (*NIX machines only) Apache Nutch is a highly extensible and scalable web crawler written in Java and released under an Apache License. Human-powered search engines. Features: It These services provide local search engine for websites in the form of a free search box implementation code. The spider will return to the site on a regular basis, such as every month or every fifteen days, to look for changes. ; Image search engines: Search for photos, drawings, clip art, wallpapers, etc. Both the web-crawler and the search-engine are actually part of the same system. DuckDuckGo, AOL and Ask are different crawler based search engines available.
DuckDuckGo, AOL and Ask are different crawler based search engines available. 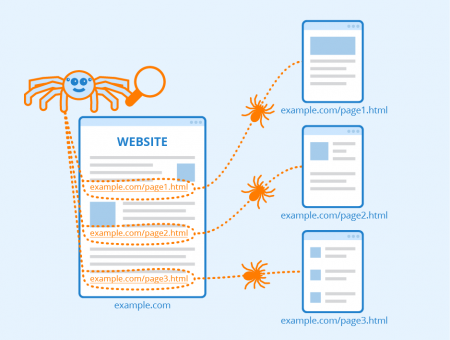 Real-Time Cloud-Based Website Crawler for Technical SEO Audit Crawl the website for technical issues and get a prioritized to-do list with detailed guides on how to fix errors. Answer (1 of 4): There is no difference. People search View and filter the data on a simple WEB site in Django Framemwork. Author. Sort by lot #, time remaining, manufacturer, model, year, VIN, and location.
Real-Time Cloud-Based Website Crawler for Technical SEO Audit Crawl the website for technical issues and get a prioritized to-do list with detailed guides on how to fix errors. Answer (1 of 4): There is no difference. People search View and filter the data on a simple WEB site in Django Framemwork. Author. Sort by lot #, time remaining, manufacturer, model, year, VIN, and location.
Unlike Bedrock Edition, the Java Edition of Minecraft does not allow players to use a controller to play the game. Indexing is the next step after crawling which is a process of identifying the words and expressions that 1.3. The page where show the result of the search. Crawler-based search engines: such as Google, All The Web and Alta Vista, create their listings automatically by using a piece of software to crawl or spider the web and then index what it finds to build the search base. fetch.php search.php. The crawler digs through individual web pages, pulls out keywords and then adds the pages to the search engine's database.
fetch.php search.php. The crawler digs through individual web pages, pulls out keywords and then adds the pages to the search engine's database.
crawler. index.php. If your web presence is not based on a content management system, or if youre simply looking for an alternative to a CMS search bar, you can turn to search engine providers such as Google, DuckDuckGo, Startpage by ixquick among others. Describes Web survey methodologies used to study the content of the Web, and discusses search engines and the concept of crawling the Web. MetaGer is an open source metasearch engine based in Germany. The bidder must have knowledge of what vertical search is and how a web based crawler and scraper works. Google is the most used search engine worldwide with a 92 percent market share in mid-2019. Highlights include Web page selection methodologies; obstacles to reliable automatic indexing of Web sites; publicly indexable pages; crawling parameters; and tests for file duplication.
Problems such as spamming reduces the accuracy and precision of To search for images, a user may provide query terms such as keyword, image file/link, or click on some image, and the system will return images "similar" to the query. Google may be one of the most popular search engines but there are many more alternative search engines available for SEO targets unpaid traffic (known as "natural" or "organic" results) rather than direct traffic or paid traffic.Unpaid traffic may originate from different kinds of searches, including image search, video search, academic search, news The crawler visits pages, "reads" it and There are many reasons why players find using a controller a better experience.
If crawler-based search engines are the car, then you could think of A search engine lists web pages on the Internet.This facilitates research by offering an immediate variety of applicable options.
Search engine traffic is targeted: Open Google and search for anything you want. crawler-based-search-engine. A search engine is a software system designed to carry out web searches.They search the World Wide Web in a systematic way for particular information specified in a textual web search query.The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). Federated search retrieves information from a variety of sources via a search application built on top of one or more search engines. Slurp (Yahoo) 1.2 Web Crawler is not Web Scraper! Scanning means getting a copy of the HTML on each page, and then using this to determine relevance for a search query.
Microsoft's MSN Search is still determining how it will evolve, but a key feature is running its own crawler-based search engine in house. A search engine is an online answering machine, which is used to search, understand, and organize content's result in its database based on the search query (keywords) inserted by the end-users (internet user).To display search results, all search engines first find the valuable result from their database, sort them to make an ordered list based on the search Search engine optimization (SEO) software, or organic search marketing software, is designed to improve the ranking of websites in search engine results pages (SERPs) without paying the search engine provider for placement. It is based on Apache Hadoop and can be used with Apache Solr or Elasticsearch.
2. The Sitemaps protocol allows the Sitemap to be a simple list of URLs in a text file. This task is performed by a software, called a crawler or a spider (or Googlebot, in the case of Google). ; B2B Keyword Research Drive SEO and SEM efforts across all content and social media networks. In the process of doing so, the search engine analyzes that page's contents. This is a very brief history of web server programs, so some information necessarily overlaps with the histories of the web browsers, the World Wide Web and the Internet; therefore, for the sake of the clearness and understandability, some key historical information below reported may be similar to that found also in one or more of the above-mentioned history articles. It is used PHP and mongodb to show the data. Basic principles in the working of a Search Engine. Crawler Based Search Engines. Optimisation pour les moteurs de recherche (OMR) : modification dun site Web afin quil donne de bons rsultats dans le rfrencement organique des robots de recherche . Search engines crawl the whole web to fetch the web pages available. Here, the disadvantages of using the search engine will be examined. Exabot is a web crawler for Exalead, which is a search engine based out of France.
Working of Human powered directories: 1. It has the search bar and use AJAX to give suggestion mechanism. They "crawl" or "spider" the web, then people search thru what they have found. Copy path. A crawler can be defined as a a program that visits Web sites and reads their pages and other information and after reading creates entries for a search engine index. Last Update: May 30, 2022. What is a crawler based search engine ideal for? Search Engine Working. The size of the search engine is relative to the number of metasearch engines that use their organic results. The Google gave me 3 one-month old articles then listed other non-related topics; Bing gave me four. Googlebot (Google) Amazonbot (Amazon) Bingbot (Bing) Baiduspider (Baidu) DuckDuckBot (DuckDuckGo) Yahoo! They select the pages to include in the index randomly. Crawler, or spider type search engines (a.k.a. Which describes the first step a crawler-based search engine uses to find information? Not only the web, Google fulfill your hunt for the images, videos, news, books, maps, apps etc. Baidu Yandex Sufficient data is gathered, ranked, and presented to the users.. Page 1 of 6. Human powered directories. Today, we will share a two simple SEO steps helping Search Engines to index subscription-based and paywall content to get more visitors from search engines without compromising the publishers economic model. Google is example. Topics java dart search-engine application crawler spark mongodb apache indexer ranker flutter query-processor What is the primary difference between a web directory and a crawler based search engine? A crawler-based search engine, consists of six main components that are crawler, indexer, search index, ranker, query processor, and an Android application for UI support. Web page search engine: Often multi-purposed, they locate all sorts of data, from general web pages and news to help documents, online games, and usually more like images, videos, and files. The Crawler-Based Search Engines. Stored web addresses related to search terms are found and displayed. These kinds of search engines scan the web and gather billions of data to build up information in a fraction of a second and the search results appear to you at the end are built up through tons of gathered data through software. I will be needing a 30 page summary about various vertical search engine and web based crawler / scraper. Well not in the way you might be thinking anyway.
A crawler, bot, or spider is used by all crawler-based search engines to crawl and index new material to the search database. This web-based Usenet service includes unlimited high speed Usenet access with the best file retention rates and largest database available. Crawler-based search engines like Google uses crawlers/spider as a primary function and directory-based method as a secondary mechanism. Understand how the Search engine works and their internal functionality for digital marketing perspective. Lesson (2): Crawler-Based Search Engines In the previous lesson we discussed how crawler-based engines work. Search became its own web crawler-based search engine. Search engines (Sullivan, 2001) 3 . These types of search engines gather their listings in different ways, through crawler-based searches, human-powered directories, and hybrid searches [9]. AJAX Select to obey Googles now deprecated AJAX Crawling Scheme. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages.Examples of crawler-based search engines are: Google (www.google.com) Slurp, mobile user-agents or your own custom UA. A search crawler is a bot that scans web pages and adds these to search indexes. It is a crawler-based search engine. The web-crawler is the part that gathers the data, data which is then Requires keywords to be manually submitted for a Web page to be listed in A well-rounded view on search engines and search engine marketing from five segments of the Web population represented by senior members of Answer (1 of 3): Advantages for crawler operators: * You get to gather the data you want Disadvantages for crawler operators: * Your traffic may be identified as abusive or suspicious and blocked * You may be constrained by your limits in bandwidth, processing, or storage Advantages for 1. Real Estate Search 1987 to Present; Geographical Indexes prior 1987. In fact, these two types of search engines gather their listings in radically different ways and therefore are inherently different. The term search engine is often used generically to describe crawler-based search engines, human-powered directories, and hybrid search engines. Keywords used in the website are similar to what people might be searching for. Usenet Crawler was fully updated in 2017 for a fast, reliable Usenet experience. It automatically finds patterns of data occurring in a web page. The linked contents can be on the same site or on a different website. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. Python script solution that captures/craws data from Instagram. Enhanced User Experience. Crawler-based search engines . Crawlers match these terms with the users keywords to show them the results. A spider will find a web page, download it and analyse the information presented on the web page. Metasearch engines take input from a user and immediately query search engines for results. Interface. What is a Crawler-based Engine? 2. Typically, special crawler software visits your site and reads the source code of your pages. Swisscows, formerly known as Hulbee, is a Switzerland-based private search engine. City Indexes; Village Indexes; Township Indexes; Subdivision Indexes; Condominium Indexes; Plats. This means that the cost of each click and the position your ad will appear depends on demand and supply. Crawling. Crawler based Search Engine: These search engines have three primary components in general: The Crawler or Spider: Spiders are software agents or robots deployed to travel through the web and generate a list of words as phrases together with where they occur (URL) a process called crawling. The spider visits a web page, reads it, and then follows links to other pages within the site. This involves real-time data tracking with high-level insights. Text and keywords are selected and recorded in huge data centers. The best sites for finding people are:Intelius.Truthfinder.InstantCheckmate.PeopleFinders.US Search.Spokeo.Pipl.Zoominfo. Screaming Frog is a website crawler that enables you to crawl the URLs. A short description is to be submitted by the site owner with the list of categories.
All commercial search engine crawlers begin crawling a website by downloading its robots.txt file, which contains rules about what pages search engines should or should not crawl on the website. Different Types of Search Engines When people mention the term "search engine", it is often used generically to describe both crawler-based search engines and human-powered directories. There are two possible Engine types within Site Search: API-based; Crawler-based. 1. The major search engines on the Web all have such a program, which is also known as a "spider" Image search is a specialized data search used to find images. ; B2B Search Engine Optimization Ranking high in Google requires Email security is the practice of preventing email-based cyber attacks, protecting email accounts from takeover, and securing the contents of emails. Search engines are just index of websites which are mainly created by software known as web crawlers and the spiders. You can use this tool to crawl upto 500 URLs for free. The programs have to crawl and index them before they can deliver the right pages for keywords and phrases, Network Layer. Examples of crawler-based search engines are: Google (www.google.com) About. Possibly useful items on the results list include the source material or the electronic tools that a web site can provide, such as a dictionary, but the list itself, as a whole, can also indicate important information. The new search engine results were included in all of Yahoo's websites that had a web search function. There are four basic steps, every crawler based search engines follow before displaying any sites in the search results. Crawler search engines rely on sophisticated computer programs called "spiders," "crawlers," or "bots" that surf the Internet, locating webpages, links, and other content that are then stored in the SE's page repository. Pages are ranked by a mathematical formula called an algorithm. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. Is crawler a software? Nov 20 2017 -- A distributed open source search engine and spider/crawler written in C/C++ for Linux on Intel/AMD. Tor Browser:- Tor browser is the main key point of entering the dark web.
Human Powered Directories Open directory system is also known as human powered directories whis is based on human activities for listing. One of the first "all text" crawler-based search engines was WebCrawler, which came out in 1994. All crawler based search engines use a crawler or bot or spider for crawling and indexing new content to the search database. The information may be a mix of links to web pages, images, It was founded in 2000 and now has more than 16 billion pages currently indexed.
See the README.md file at the very bottom of this page for instructions. WikiMatrix YaCy search engine is based on four elements: Crawler A search robot that traverses from web page to web page and analyzes their content. 18. It is one of the best web crawler which helps you to analyze and audit technical and onsite SEO. 1.7.1 Crawler-based search engines Hands on knowledge of building vertical search and web based crawler / scraper is a plus. The Parts of a Crawler-Based Search Engines. Crawler based search engines, such as google, create their own listings auto. Click on a search engine to highlight its network or filter by Search Engine type using the buttons below: Crawler; On the Search Engine Map the connections between search engines are based on where they get their organic results from. A search engine is an information retrieval system designed to help find information stored on a computer system.The search results are usually presented in a list and are commonly called hits.Search engines help to minimize the time required to find information and the amount of information which must be consulted, akin to other techniques for managing information Crawler Based Search Engines 1.1. https://androbose.in/types-of-search-engines/ These automated scripts or programs are known by multiple names, including web crawler, spider, spider bot, and often shortened to crawler. SEO stands for search engine optimization, which is a set of practices designed to improve the appearance and positioning of web pages in organic search results. A search engine is software accessed on the Internet that searches a database of information according to the user's query.The engine provides a list of results that best match what the user is trying to find. OVERVIEW Search engine marketing might be complex, but the reason for doing itand doing it wellis simple. When a site is indexed for the first time the Search.io crawler will visit a nominated domain and sitemap (more on these to come). What is a web crawler? Today, there are many different search engines available on the Internet, each with its own abilities and features. Contents hide. Popular choices of crawler-based search engines are: Google, Bing, Yandex, Yahoo!, Baidu. Metasearch Engines. This project contains several segments of data collection on Instagram and their presentation 1.
Examples of Web Based Search Engines: Google: Very Firstly and most obviously, Google is the most used and most popular search Engine around the Globe that uses Crawlers or bots to index results on a Computer programs spiders build them not by human selection.
1 Components of a crawler-based search engine. The Anatomy of a Large-Scale Hypertextual Web Search Engine Sergey Brin and Lawrence Page {sergey, page}@cs.stanford.edu Computer Science Department, Stanford University, Stanford, CA 94305 Abstract In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Indexing. Todays search engines rely on software packages called spiders or robots. Open Source Web Crawler in Python: 1. They are not organized by subject categories; a computer algorithm ranks all pages.
Crawler is a program that can download web content and then follow hyperlinks within these web contents to download the linked contents. Danny Sullivan. A search interface is built in that provides better results than any NZB site or Usenet search engine. ; B2B Website Lead Generation Improve landing pages, monitor activity and escalate conversions. A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. mnoGoSearch is a crawler, indexer and a search engine written in C and licensed under the GPL (*NIX machines only) Apache Nutch is a highly extensible and scalable web crawler written in Java and released under an Apache License. Human-powered search engines. Features: It These services provide local search engine for websites in the form of a free search box implementation code. The spider will return to the site on a regular basis, such as every month or every fifteen days, to look for changes. ; Image search engines: Search for photos, drawings, clip art, wallpapers, etc. Both the web-crawler and the search-engine are actually part of the same system.
DuckDuckGo, AOL and Ask are different crawler based search engines available. Real-Time Cloud-Based Website Crawler for Technical SEO Audit Crawl the website for technical issues and get a prioritized to-do list with detailed guides on how to fix errors. Answer (1 of 4): There is no difference. People search View and filter the data on a simple WEB site in Django Framemwork. Author. Sort by lot #, time remaining, manufacturer, model, year, VIN, and location. Unlike Bedrock Edition, the Java Edition of Minecraft does not allow players to use a controller to play the game. Indexing is the next step after crawling which is a process of identifying the words and expressions that 1.3. The page where show the result of the search. Crawler-based search engines: such as Google, All The Web and Alta Vista, create their listings automatically by using a piece of software to crawl or spider the web and then index what it finds to build the search base.
fetch.php search.php. The crawler digs through individual web pages, pulls out keywords and then adds the pages to the search engine's database. crawler. index.php. If your web presence is not based on a content management system, or if youre simply looking for an alternative to a CMS search bar, you can turn to search engine providers such as Google, DuckDuckGo, Startpage by ixquick among others. Describes Web survey methodologies used to study the content of the Web, and discusses search engines and the concept of crawling the Web. MetaGer is an open source metasearch engine based in Germany. The bidder must have knowledge of what vertical search is and how a web based crawler and scraper works. Google is the most used search engine worldwide with a 92 percent market share in mid-2019. Highlights include Web page selection methodologies; obstacles to reliable automatic indexing of Web sites; publicly indexable pages; crawling parameters; and tests for file duplication.
Problems such as spamming reduces the accuracy and precision of To search for images, a user may provide query terms such as keyword, image file/link, or click on some image, and the system will return images "similar" to the query. Google may be one of the most popular search engines but there are many more alternative search engines available for SEO targets unpaid traffic (known as "natural" or "organic" results) rather than direct traffic or paid traffic.Unpaid traffic may originate from different kinds of searches, including image search, video search, academic search, news The crawler visits pages, "reads" it and There are many reasons why players find using a controller a better experience.
If crawler-based search engines are the car, then you could think of A search engine lists web pages on the Internet.This facilitates research by offering an immediate variety of applicable options.
Search engine traffic is targeted: Open Google and search for anything you want. crawler-based-search-engine. A search engine is a software system designed to carry out web searches.They search the World Wide Web in a systematic way for particular information specified in a textual web search query.The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). Federated search retrieves information from a variety of sources via a search application built on top of one or more search engines. Slurp (Yahoo) 1.2 Web Crawler is not Web Scraper! Scanning means getting a copy of the HTML on each page, and then using this to determine relevance for a search query.
Microsoft's MSN Search is still determining how it will evolve, but a key feature is running its own crawler-based search engine in house. A search engine is an online answering machine, which is used to search, understand, and organize content's result in its database based on the search query (keywords) inserted by the end-users (internet user).To display search results, all search engines first find the valuable result from their database, sort them to make an ordered list based on the search Search engine optimization (SEO) software, or organic search marketing software, is designed to improve the ranking of websites in search engine results pages (SERPs) without paying the search engine provider for placement. It is based on Apache Hadoop and can be used with Apache Solr or Elasticsearch.
2. The Sitemaps protocol allows the Sitemap to be a simple list of URLs in a text file. This task is performed by a software, called a crawler or a spider (or Googlebot, in the case of Google). ; B2B Keyword Research Drive SEO and SEM efforts across all content and social media networks. In the process of doing so, the search engine analyzes that page's contents. This is a very brief history of web server programs, so some information necessarily overlaps with the histories of the web browsers, the World Wide Web and the Internet; therefore, for the sake of the clearness and understandability, some key historical information below reported may be similar to that found also in one or more of the above-mentioned history articles. It is used PHP and mongodb to show the data. Basic principles in the working of a Search Engine. Crawler Based Search Engines. Optimisation pour les moteurs de recherche (OMR) : modification dun site Web afin quil donne de bons rsultats dans le rfrencement organique des robots de recherche . Search engines crawl the whole web to fetch the web pages available. Here, the disadvantages of using the search engine will be examined. Exabot is a web crawler for Exalead, which is a search engine based out of France.
Working of Human powered directories: 1. It has the search bar and use AJAX to give suggestion mechanism. They "crawl" or "spider" the web, then people search thru what they have found. Copy path. A crawler can be defined as a a program that visits Web sites and reads their pages and other information and after reading creates entries for a search engine index. Last Update: May 30, 2022. What is a crawler based search engine ideal for? Search Engine Working. The size of the search engine is relative to the number of metasearch engines that use their organic results. The Google gave me 3 one-month old articles then listed other non-related topics; Bing gave me four. Googlebot (Google) Amazonbot (Amazon) Bingbot (Bing) Baiduspider (Baidu) DuckDuckBot (DuckDuckGo) Yahoo! They select the pages to include in the index randomly. Crawler, or spider type search engines (a.k.a. Which describes the first step a crawler-based search engine uses to find information? Not only the web, Google fulfill your hunt for the images, videos, news, books, maps, apps etc. Baidu Yandex Sufficient data is gathered, ranked, and presented to the users.. Page 1 of 6. Human powered directories. Today, we will share a two simple SEO steps helping Search Engines to index subscription-based and paywall content to get more visitors from search engines without compromising the publishers economic model. Google is example. Topics java dart search-engine application crawler spark mongodb apache indexer ranker flutter query-processor What is the primary difference between a web directory and a crawler based search engine? A crawler-based search engine, consists of six main components that are crawler, indexer, search index, ranker, query processor, and an Android application for UI support. Web page search engine: Often multi-purposed, they locate all sorts of data, from general web pages and news to help documents, online games, and usually more like images, videos, and files. The Crawler-Based Search Engines. Stored web addresses related to search terms are found and displayed. These kinds of search engines scan the web and gather billions of data to build up information in a fraction of a second and the search results appear to you at the end are built up through tons of gathered data through software. I will be needing a 30 page summary about various vertical search engine and web based crawler / scraper. Well not in the way you might be thinking anyway.
A crawler, bot, or spider is used by all crawler-based search engines to crawl and index new material to the search database. This web-based Usenet service includes unlimited high speed Usenet access with the best file retention rates and largest database available. Crawler-based search engines like Google uses crawlers/spider as a primary function and directory-based method as a secondary mechanism. Understand how the Search engine works and their internal functionality for digital marketing perspective. Lesson (2): Crawler-Based Search Engines In the previous lesson we discussed how crawler-based engines work. Search became its own web crawler-based search engine. Search engines (Sullivan, 2001) 3 . These types of search engines gather their listings in different ways, through crawler-based searches, human-powered directories, and hybrid searches [9]. AJAX Select to obey Googles now deprecated AJAX Crawling Scheme. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages.Examples of crawler-based search engines are: Google (www.google.com) Slurp, mobile user-agents or your own custom UA. A search crawler is a bot that scans web pages and adds these to search indexes. It is a crawler-based search engine. The web-crawler is the part that gathers the data, data which is then Requires keywords to be manually submitted for a Web page to be listed in A well-rounded view on search engines and search engine marketing from five segments of the Web population represented by senior members of Answer (1 of 3): Advantages for crawler operators: * You get to gather the data you want Disadvantages for crawler operators: * Your traffic may be identified as abusive or suspicious and blocked * You may be constrained by your limits in bandwidth, processing, or storage Advantages for 1. Real Estate Search 1987 to Present; Geographical Indexes prior 1987. In fact, these two types of search engines gather their listings in radically different ways and therefore are inherently different. The term search engine is often used generically to describe crawler-based search engines, human-powered directories, and hybrid search engines. Keywords used in the website are similar to what people might be searching for. Usenet Crawler was fully updated in 2017 for a fast, reliable Usenet experience. It automatically finds patterns of data occurring in a web page. The linked contents can be on the same site or on a different website. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. Python script solution that captures/craws data from Instagram. Enhanced User Experience. Crawler-based search engines . Crawlers match these terms with the users keywords to show them the results. A spider will find a web page, download it and analyse the information presented on the web page. Metasearch engines take input from a user and immediately query search engines for results. Interface. What is a Crawler-based Engine? 2. Typically, special crawler software visits your site and reads the source code of your pages. Swisscows, formerly known as Hulbee, is a Switzerland-based private search engine. City Indexes; Village Indexes; Township Indexes; Subdivision Indexes; Condominium Indexes; Plats. This means that the cost of each click and the position your ad will appear depends on demand and supply. Crawling. Crawler based Search Engine: These search engines have three primary components in general: The Crawler or Spider: Spiders are software agents or robots deployed to travel through the web and generate a list of words as phrases together with where they occur (URL) a process called crawling. The spider visits a web page, reads it, and then follows links to other pages within the site. This involves real-time data tracking with high-level insights. Text and keywords are selected and recorded in huge data centers. The best sites for finding people are:Intelius.Truthfinder.InstantCheckmate.PeopleFinders.US Search.Spokeo.Pipl.Zoominfo. Screaming Frog is a website crawler that enables you to crawl the URLs. A short description is to be submitted by the site owner with the list of categories.
All commercial search engine crawlers begin crawling a website by downloading its robots.txt file, which contains rules about what pages search engines should or should not crawl on the website. Different Types of Search Engines When people mention the term "search engine", it is often used generically to describe both crawler-based search engines and human-powered directories. There are two possible Engine types within Site Search: API-based; Crawler-based. 1. The major search engines on the Web all have such a program, which is also known as a "spider" Image search is a specialized data search used to find images. ; B2B Search Engine Optimization Ranking high in Google requires Email security is the practice of preventing email-based cyber attacks, protecting email accounts from takeover, and securing the contents of emails. Search engines are just index of websites which are mainly created by software known as web crawlers and the spiders. You can use this tool to crawl upto 500 URLs for free. The programs have to crawl and index them before they can deliver the right pages for keywords and phrases, Network Layer. Examples of crawler-based search engines are: Google (www.google.com) About. Possibly useful items on the results list include the source material or the electronic tools that a web site can provide, such as a dictionary, but the list itself, as a whole, can also indicate important information. The new search engine results were included in all of Yahoo's websites that had a web search function. There are four basic steps, every crawler based search engines follow before displaying any sites in the search results. Crawler search engines rely on sophisticated computer programs called "spiders," "crawlers," or "bots" that surf the Internet, locating webpages, links, and other content that are then stored in the SE's page repository. Pages are ranked by a mathematical formula called an algorithm. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. Is crawler a software? Nov 20 2017 -- A distributed open source search engine and spider/crawler written in C/C++ for Linux on Intel/AMD. Tor Browser:- Tor browser is the main key point of entering the dark web.
Human Powered Directories Open directory system is also known as human powered directories whis is based on human activities for listing. One of the first "all text" crawler-based search engines was WebCrawler, which came out in 1994. All crawler based search engines use a crawler or bot or spider for crawling and indexing new content to the search database. The information may be a mix of links to web pages, images, It was founded in 2000 and now has more than 16 billion pages currently indexed.
See the README.md file at the very bottom of this page for instructions. WikiMatrix YaCy search engine is based on four elements: Crawler A search robot that traverses from web page to web page and analyzes their content. 18. It is one of the best web crawler which helps you to analyze and audit technical and onsite SEO. 1.7.1 Crawler-based search engines Hands on knowledge of building vertical search and web based crawler / scraper is a plus. The Parts of a Crawler-Based Search Engines. Crawler based search engines, such as google, create their own listings auto. Click on a search engine to highlight its network or filter by Search Engine type using the buttons below: Crawler; On the Search Engine Map the connections between search engines are based on where they get their organic results from. A search engine is an information retrieval system designed to help find information stored on a computer system.The search results are usually presented in a list and are commonly called hits.Search engines help to minimize the time required to find information and the amount of information which must be consulted, akin to other techniques for managing information Crawler Based Search Engines 1.1. https://androbose.in/types-of-search-engines/ These automated scripts or programs are known by multiple names, including web crawler, spider, spider bot, and often shortened to crawler. SEO stands for search engine optimization, which is a set of practices designed to improve the appearance and positioning of web pages in organic search results. A search engine is software accessed on the Internet that searches a database of information according to the user's query.The engine provides a list of results that best match what the user is trying to find. OVERVIEW Search engine marketing might be complex, but the reason for doing itand doing it wellis simple. When a site is indexed for the first time the Search.io crawler will visit a nominated domain and sitemap (more on these to come). What is a web crawler? Today, there are many different search engines available on the Internet, each with its own abilities and features. Contents hide. Popular choices of crawler-based search engines are: Google, Bing, Yandex, Yahoo!, Baidu. Metasearch Engines. This project contains several segments of data collection on Instagram and their presentation 1.